
Episode 13 – Solution lifecycle
Welcome to the first episode of our podcast season 2! Today we are talking about the Solution Lifecycle in architecture – what it is and why it is important to you.
Architecture development and analysis does not happen in a vacuum, but are embedded in a lifecycle. New tools like Process Mining and Task Mining make it sound as if you don’t need other tools and techniques anymore, but quite the opposite is the case – traditional analysis techniques are still needed to support all phases of the solution lifecycle. We are talking about:
- What is a “solution” and what are the layers and phases of the lifecycle (see also graphic below)?
- Give examples of two analysis types and when to use which one best
- Simulation
- Process Mining
- The value of this iterative approach and the cautions
- The iterative nature of it and the impact on developing your overall architecture approach
Please reach out to us by either sending an email to hello@whatsyourbaseline.com or leaving us a voice message by clicking here.

Ep. 13 – Solution Lifecycle – What's Your Baseline? Enterprise Architecture & Business Process Management Demystified
Additional information
- Article that I wrote about the solution lifecycle earlier: SOLUTION/PROCESS LIFECYCLE – ARCHITECTURE IS MORE THAN “DRAW IT AND FORGET IT”
- Solution Lifecycle graphic
- Mike Idengren‘s video about the agile runway and development concept
Credits
Music by Jeremy Voltz, www.jeremyvoltzmusic.com
- CP1 (Welcome)
- Airplane Seatbelt (Interlude 1)
- Lofi Lobby Loop (Interlude 2)
- With You Knew Me (Interlude 3)
- South Wing (Outro)
Transcript
(The transcript is auto-generated and was slightly edited for clarity)
Roland: Hey J-M, welcome to episode 13 of this favorite podcast of yours. Are you back from hibernation?
J-M: Not quite ready to be back yet. I had a nice little winter break where I had a chance to finally unwind and decompress and I don’t know if I’m ready to get right back to it, but this is a great time to get started with the What’s Your Baseline podcast! I know you said episode 13 and technically it is, but it’s also the beginning of our second season. Hurray! Thank you so much to everyone who’s been listening so far and we’re really excited to bring lots of amazing content in our upcoming 5-6 months.
Roland: So I hope you’re all excited about season two of our favorite podcast here, where we have some incredible topics for you, and I don’t want to repeat the trailer again, but be prepared for a bunch of interviews with thought leaders and company leaders from our favorite industries of architecture and process management.
J-M: You’ve got some great ones on the docket there. I’m really excited.
Roland: Yeah, but J-M. What’s on the docket for our show today?
J-M: Well, that’s a really great question Roland, and today we’re going to kick off season two really starting to get some fundamental principles behind how we operate architecture, and to do that we want to talk about a solution lifecycle. So for our topic today, we want to really dig into that solution lifecycle and go through each of the different phases and see what it’s going to take to make this successful and talk about some of the value that you can get from adopting this approach. Seeing a solution lifecycle taking each phase in turn and extracting that value along the way, and I mean, I can’t think of anyone better to kick this off. I know, Roland, you’ve been preaching about the solution lifecycle. You’ve got some great graphics. I know you’re going to host up at whatsyourbaseline.com but get us kicked off, talk about architecture, development and analysis. How do we do this and what is our approach and lead us into this solution lifecycle?
Roland: Oh, absolutely, and I’m glad that you mentioned it because I wrote an article about it and I said: hey, is architecture just drawing and forgetting it? Some people seem to look at this, you know; I create my artifact; I’m done, and I move on. And that’s one of the attitudes that I’m really not a big fan of, because at the end of the day, what you want is you want to build up some sustainable practice around your solution development. Speaking of that, as I said before, architectural development and the analysis that you do does not happen in a vacuum, right? It’s embedded in some form of life cycle, and when you talk to agile folks, they might come back with something like Dev/Ops. I like that principle. You build it, you own it. I like that very much, and I think what we as a practice should do is take a step back and have a look at how all those artifacts and analysis and all that stuff that we create fits into a bigger picture, and that’s what we’re going to talk about today.
J-M: And I wanted to start off this conversation with a caveat. I know that there’s a lot of folks who will talk about new technologies and tools that may seem to take away from the need for this disciplined approach. I know that process mining / task mining, things like that say that data is everything you need. We said in our 10 Things I’ve Learned (and I really like this phrase) that “data may be king, but context is its crown” And that’s absolutely true more than ever, even in the face of new technologies. You need the process lifecycle, the solution lifecycle, and you need to go through it as a human being. As a practitioner with expertise and experience and context and the ability to parse information to be able to effectively enact change, effectively maintain architecture. And that’s important. It can’t be done automatically.
Roland: And there are some practical reasons behind that as well. For everyone who has talked to a process mining vendor or RPA vendor and were asking about the cost, I’m pretty sure you got the big sticker shock because they will tell you: “well for base installation and say one live process” (so process that’s connected to a runtime system so that you can always the latest and greatest), well, you might easily fork over 40 to 100 grand U.S. dollars depending on the size of the process, the size of the data volume, and all those type of things. So now when we look at frameworks like the APQC process reference model that has like 1200 to 1300 processes, well, you do the math. So cost is definitely an issue, and I think this is one of the things where you say it’s great that you have that technology, which is actually pretty great. I’m a big fan of these mining technologies, but on the other side it comes with a cost, so you want to apply that to the most valuable scenarios that you can figure out.
J-M: Yeah, and you’ll know that there are some scenarios that are more tailored to the use of these types of technologies. Things with automation, things where you’ve got a lot that you can affect with this solution architecture that you can measure, manage and then be able to implement on. And you can use things like machine learning and AI predictive analysis to be able to try and improve with data as the driver for this sort of automated assessment of weakness and automated next best action proposal for the process. But that’s not the case with all these things, and particularly we need to understand and tailor our solutions to the problems that we’re seeing.
Roland: Yeah, that’s true. The second point that speaks a little bit against the applications of those technologies is that they are typically based on past data, right? So they cannot really predict the future as of today, at least in the tools. Maybe they have become smarter, but today they are based on the existing data patterns right? And so you don’t have potential future changes that you plan and in your analysis and the impact that those might have.
J-M: Yeah, I mean I guess people will often say that you know when you can use trendlines, you can extrapolate what might happen with the organization, but that’s the case of a sort of single threaded analysis. You can see how the variables are affected by the patterns of behavior one at a time, but being able to understand a future state, a future state architecture, a future state business – like the whole business plan could change, your organization could pivot quite a lot, and just even in the way you deliver, responding to market trends and customer demands, that’s going to be really difficult to predict. And so right now, we don’t see a lot of models that can effectively scale the prediction of the future in a way that would allow you to do it entirely with automation. You need a human touch. In particular, you need business expertise and context, as I said before, to bring this to life.
Roland: Yeah, I agree, and as good as they are, and when you look at the vendors that will tell you:” oh yeah, we have simulation built in”. Which I would call maybe a glorified “what-if scenario” based on the existing data. But when you look at true simulation tools and when you look at true simulation efforts, well, the distinction is they are forward looking. It’s not “what have I done in the past?” It is “what am I going to do in the future?” And then they run the simulation with all those variables and all that stuff that we’re going to talk about in our second segment of this show in more depth.
J-M: Yeah, we talk a lot more about that, but, you know, just as a sort of preview. The cautionary tale here is: a simulation also needs to understand and account for flow changes rather than simply optimization around resources. And a lot of times machine models don’t work well with that. Being able to re-engineer? That’s not in the design.
Roland: Yeah, and then lastly, future state models have additional purposes, independent of the view. Might be processes or apps or whatever in your architecture structure. For example, a benefit is bringing people on the same page, literally. You put something on a virtual piece of paper and you discuss it with people, and everybody says, oh, this is how it should work. They could also be an input for your org change management activities like communication and training, answering the question “what will change” or “what has changed” and maybe before the implementation is actually over.
J-M: And that would be ideal. So we’ve been talking about a lot of these things, but Roland, let’s boil it down to the big question. What is the solution and what is the solution lifecycle?
Roland: That is a very good question. I’m glad that you asked, because that’s one of those terms that has been used very arbitrarily in the past. So when you talk to a software vendor, they obviously call their software the solution, right? When you talk to people who change organizations, they will say their org change is the solution. I think in all reality, a solution is more than that. A solution, by my definition, is a capability that you implement that you bring to fruition. And as we know from a previous episode, the capability is obviously comprised of multiple aspects. It’s the process, it’s the people, it’s the applications, it’s the data, it’s the location, it’s the skills – all those different things that all come together. So going forward, if we try to define a solution, then I would say a solution is a capability that was brought to life.
J-M: Right, and as you said, there’s lots of different components to this capability, and as we go through the solution lifecycle and we start to talk about some extended use cases and analysis techniques like simulation, we’ll see how many of these auxiliary components come into play when we’re making the decision on how to move forward. So let’s go through the different phases, ’cause once again we’ve got a great graphic for this. So another pitch for the whatsyourbaseline.com website that includes a couple of lanes and a couple of phases. So let’s take them through it, Roland, and I think this is a great opportunity to lead them down our path. Where would you start? Because we’re looking at the graphic. Let’s say everyone is not in their cars. Where would they start looking?
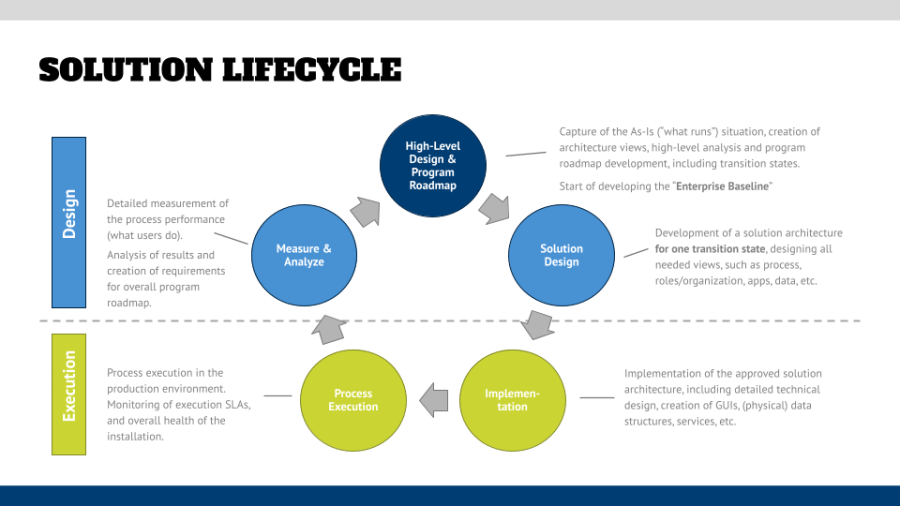
Roland: I just wanted to give that public service announcement, so if you’re driving and listening to it, don’t look at the show notes. If you’re in a safe place, open the show notes. Look at the graphic that we put into it. So when you look at the solution lifecycle, what you typically see is 2 lanes or two layers. One is the design layer. This is where you do your intentional design of what shall be changed, what shall be implemented. And then the second layer underneath is your execution layer that includes your implementation and running the systems. So within those two layers there are five phases being put on it and in a circle, so it’s all iterative. But when you look at them, typically you start with a high level structure and program roadmap development phase, to not use the overextended word “strategy phase” for this. What is that? What is that first phase? The first phase has basically 2 objectives. The first one is to build something that I would like to call an enterprise baseline, which is the description of ‘what runs’. Which processes are live, which applications do you currently have, what’s the data flow and all those things that frameworks like TOGAF will explain ad nauseam what should be in there. But the idea of that is you put things to paper that you then can analyze and you find those areas for improvement. That could be reduction of technical debt for example. Or that could be an improvement of processes as another example, and the ideas. And that’s the second big point, is to come up with a program road map to identify: these are the things that we need to change. These are the things that we need to change in a certain sequence and then define your transition states to say OK, this is where I’m today. This is where I want to be in six months, 12 months, 18 months from now.
J-M: And I want to put a caution in here, because I know this happens a lot, but you want to do this in the order that Roland is saying rather than the opposite. And so many times, Roland, you and I will sit with an organization that says OK, so here is what we’d like to do. And we ask the question: “OK, so how did you come to that realization, and where are you today?” They answer: “we decided that around a boardroom and where we are today doesn’t really matter. Here’s what we want to do.” And that gives you such a rip-out of context and such a disadvantage when trying to make the transition because you don’t know why you made the decision. It was somebody sort of convincing that this is what we needed to do as an organization, or, you know, this was a strategic initiative that was, you know, there’s some idea and consensus around that it’s important for the company, but it wasn’t that understanding of what we have and what’s weak about it. It’s just a generalized goal, and being able to drive off the “as-is”, “what’s needed” is going to give you a much closer alignment with what’s actually going to work.
Roland: And maybe to just chime in on this. As part of your enterprise baseline, you should obviously come up with some artifacts talking around your strategy. What are the strategic objectives that you have? How are they aligned to your initiatives that you run? How are they aligned to whatever, your applications, your capabilities, all those different artifacts that you bring to fruition. And to be quite honest, I’ve seen just a few clients who actually had those thoughts. When it came to the implementation of a new system, everybody’s all excited about those features and benefits and whatnot. But they never truly made the connection to the strategy because the organization didn’t articulate the strategy well enough. So yeah, as part of the enterprise baseline, it’s all those aspects. It’s strategy, it’s the business architecture, the technology, the data, all those things that you should put in [place]. But again, the second point is not only creating this stuff and putting it in relation. The second part is to do something with it. Find the improvements, build up your road map, define your transition states that you want to have.
J-M: And that goes into solution design. That is the next piece of the puzzle. So after the high level design and program road map, we want to actually define the architecture, create documentation, be able to involve collaborators and stakeholders in the creation of something tangible to which you are going to change.
Roland: Agreed, and to be very, very clear, when J-M talks about architecture, we’re not talking about apps only, right? Architecture in the sense as TOGAF sees it. So you have the strategy, the business architecture, the applications, and so on. All that stuff there. It must all come together and the criteria for this is that you define your solution architecture for one transition state and only one. So while in the previous phase you looked at where do I want to be 6, 12, 18 months from now. Well, in the solution design phase you would look at: what does the landscape look like six months from now?
J-M: Yeah, you want to get it done one at a time, right? Otherwise you’re going to overwhelm yourself. And also, you’re not going to consider all the externalities that are going to come along the way. You need to look forward, look at what you can handle right now so that you’re able to get to that state. And then you can look at the next state, and that’s really important. And talking about getting to those states, once we have the solutions designs in place, what do we do next with them?
Roland: So, yeah, but before we get to this point, how do I implement it? Maybe one thing that some naysayers might come in and say J-M, you’re talking about that old waterfall process. The answer from me to that point is no, right? The fact that you define where you want to be in 6, 12, 18 months from now and build a design for a state that says “where do we want to be in six months from now” does not prevent being agile, right? So you do your iterations there. You have two week increments. Your four week increments. You do the synchronization between your different work streams, and your agile teams and all that stuff within that time frame. But somehow at some point in time you need to come up with a bigger picture, because then if you don’t have this, the integration of the different agile artifacts that you do is not possible. You will not realize when you’re behind, when you don’t have the North Star. Your solution design is looking for that state in time when you go live and you really bring something to fruition on a bigger scale.
J-M: Let’s bring all these things together. And that’s really important when we look at implementation. Let’s take a look at our one transition state that we’ve focused on, and let’s actually create the technical solution. And now we’re moving from our lane of design to our lane of execution. And Roland, tell me about some of the challenges associated with implementation.
Roland: So first of all, implementation doesn’t necessarily mean that you implement a system, even though that might be the most used use case. It also could be just a change in the process without changing anything else. Or it could be a reorganization without changing systems. But in general, you typically see this when you do system implementations. And the big challenge that you have is there might be a difference between what was designed and what was implemented. Because during the implementation phase decisions might have to be made, and then you can’t get the right stakeholder or decision maker, but you have that deadline and then you take a wild guess and you would rather make a decision and ask for forgiveness later or whatever. All those things that happen in a real life project so that there could be a delta between, or a difference between what was designed and what was implemented.
J-M: And we want to make sure we capture that in documentation, otherwise we’re going to lose the thread, because, remember, if you’re doing one transition state at a time, you need to be iterative.
Roland: A good tool will support this, right? So you can synchronize or update your designs accordingly and get the buy-in from the stakeholders. But the more important thing is that at some point in time you go live. So what happens now when you go live, your “as implemented” becomes the new “what runs”. So it becomes part of the enterprise baseline so that the next group after you can then do their analysis from a solid information base.
J-M: That means process execution necessarily needs to lead into measurement and analysis. And I believe very, very strongly in this, because of course it’s really hard to improve what you can’t measure. And it’s also hard to justify the next project if you can’t capture the business benefits of this project. And so when we take a look at moving from our third bullet implementation into the 4th in ‘execution’, which is “process execution”, we are also putting those hooks in to get back into the design side / the design lane here where we’re talking about creating visualizations, creating data sources that can be drawn upon from your process execution. You’re also creating other sorts of things that don’t necessarily require technical solutions. Things like employee feedback and surveys to help understand the efficacy of your solution. One of the things that I do with a lot of my organizations that I work with is talk about feedback from end consumers of the work you’re doing. So what do your users think about your systems? What do your people think about your processes? They’re going to give you great information that you can leverage to understand not just what’s most efficient, but what’s going to work best.
Roland: Yeah, I think you should distinguish between two things. One is on the execution side as the step four, as you just mentioned, is doing the actual execution. I think the focus there is on “do I meet my operational SLAs?” If I’m a manufacturing shop, do I produce the right amount of widgets in the right quality at a time? And I want to know: do I run my business well? Or if you’re in a financial service organization, you want to have a look at: “do I have enough cases underwritten at the end of the day, and if not, where do I have to put them?” So what you would do there is you would create dashboards that would give you that information based obviously on systems. Having said that, that’s a slight different twist when you go back into the design phase. When you look at measure and analyze where also your employee feedback in all those types of things might come in. But maybe, J-M, you walk us through the last phase of the solution lifecycle.
J-M: Yeah, so let’s dig into that measure and analyze, the first thing you want to do is you want to get a detailed measurement of what people are actually doing and the performance thereof. And so that’s going to be making sure that you tie it back to the strategy and the KPIs you set out for yourself. Because, remember, you’re supposed to define those far in advance. So we can see if we’ve met our KPI targets along the axis of the KPIs that we have decided are important to us. And then we’re going to take that and present that in visualizations that have things like emergent features, and you know, coordination between different widgets and charts that help us understand how well we’ve achieved our targets, where we still struggle, and how we can tie that back into an additional requirement set or additional components on our road map. Remember, we’re talking about one transition state at a time, so we’re able to remain agile and adapt to the efficacy of our solutions, but only if we can see them and then tie them back to that strategic program road map. Does that make sense?
Roland: Yeah it does. It does, and maybe it just closes it out. If people are confused when they listen to this, this is obviously the phase where we talk about those technologies like process mining and task mining and machine learning and AI and all those wonderful things. Again, just to reinforce it, this is basically taking a step back. Take a step back to see what users are doing. Have a look at them to see if they follow your “as designed” solution design.
J-M: Yeah, “Compliance”.
Roland: Right compliance is the big word, and your GRC folks will love that. But the main idea is to do that analysis to find new areas of improvement so that you then can go back to your first phase in that circle where you say, OK, this is an area I want to have a deeper look at. Is it worth improving this area going forward?
J-M: And that’s really those five steps we went through. So just to summarize again, step #1 is our high level design road map. Step #2 is the solution design itself for one transition state. Step #3 in our execution lane is implementation. Step #4 is our process execution, the run of things, and step #5 back into the design lane is the measurement and analysis of the running systems. And I wanted to take this to a call to action. Because I want you to think about improvement projects you’re involved in right now. Our dear listeners, what are you doing? How are you involved in these initiatives and what phase of that life cycle are you currently in? So for you, what’s next? What was stated as next? And are you on the right track given the five cycle phases we just went through. We’ll leave you for a second and be back in a moment with part two of our exploration of the solution lifecycle.
Musical Interlude: “Airplane Seatbelt” Jeremy Voltz
Roland: Welcome back to the next segment in our show, which is, as you know by now, the “how-to” segment in all of our shows. And for this episode, we’re thinking about highlighting two areas of the solution lifecycle. One is simulation, it’s the forward-looking future state prediction of the future before you start wrenching, and the second one is process mining as the after-the-fact analysis of what has actually happened.
J-M: So let’s get started and with that I wanted to dig into simulation. So I know at a high level there’s a lot of thoughts around simulations such as Discrete Event and Monte Carlo. Can you explain those to us and get us started on this path of simulation?
Roland: Yeah, but I will do that very briefly because there’s obviously tons of Wikipedia articles if you really want to know how that works, but in general, when you look at Monte Carlo simulation, it’s a calculation of probabilities. So when you have a process that goes through something, you say oh, in 80%, it goes here and this and that and that. And if you multiply that, you get a result. The other way that simulation engines do is discrete event simulations, and that’s literally running down each individual simulation according to the parameters that you’ve set. So if you say you have a process that happens 50 times a day for three months, guess what? Now my math is too bad. So you have 50 times 90 cases that get run through that simulation. And that is obviously a more hands-on approach that might give you a little bit better result when it comes to the different things that you want to get out of a simulation. But J-M, talk a little bit about what kind of information you actually need and what you use in simulations.
J-M: That’s a great question, so for those of you who haven’t done simulation before, welcome to the “Fun Times”. For those of you who do, this might be a little bit of a refresher, but it’s a great place to start the conversation. So when we look at simulation, there’s a little bit of information you’re going to need in order to exact a simulation that you can do something with and with. The first piece of this puzzle is you need to have some model upon which the simulation is going to be built, and there’s a lot of different ways you can construct this model. The way that I happen to like constructing it is, it looks like a flow, a process flow, and that will help us understand the ordering of activities when we run through a simulation, particularly in the context of a process. So you’re looking to simulate that process model, so the flow itself comes with a couple of different components to it. The first is you need to have the order of activities and the activities themselves, as well as you need to have the different paths those activities might go between. So, the probabilities that you could go from one variant or to the other. A perfect example is: how many of our sales orders come through that require a secondary check on them. Well, 10%, so 10% of the time you’re going to go down this variant path. And once you have the basic flow established, you’ve got the first piece of the puzzle and oftentimes a visualization of what your process looks like. The next thing you’re going to want to do is help to understand what it takes for your process to execute, and that’s where we get into our very first layer of attribution when we come to timing. Now, timing can be quite a complex component of processes. We see different types of time. So a perfect example is processing time. The amount of time it takes for a single activity to execute on average, or perhaps a curve or a formula by which you can calculate how long something might take in any given time. You could also have wait times, so there’s burdens put up on a simulation. You have to wait a certain amount of time between these two steps, or even things like throughput time for multiple different steps where you don’t necessarily see the intervening steps. An example is like black boxing a whole system in between two different steps. You want to say: “oh, there’s an actual throughput time that’s going to be required between these two steps. We need to have that calculated as part of our simulation.”
Roland: Yeah, and to be very, very clear, wait time in a manufacturing process literally could mean waiting until the paint is dry, right? Or when you think about the preparation time that you need if you have a machine, for example, in a car manufacturing process where you stamp out fenders out of pieces of aluminum or steel and then you have to change the jig, that’s also a time that you need to calculate that preparation time before the next step in that process can be run.
J-M: You often see that referred to as orientation time. That’s a handy number to put on it, but I find that that, you know, those are very physical process representations, and when we’re looking at business process, oftentimes those don’t come into play quite as much, but they’re really good to know if you’re looking at that very heavy manufacturing context. And then we start. So once we have those two things in place, you have the flow and you have your time, you can run event simulations on that. You can understand. OK, so how long is this going to take, which process steps are going to on average take longer, and what paths am I going to go down more often? But that doesn’t give you as much information as you really need to extract a lot of the value out of it, and that value comes with a couple of different types of attribution and relationships. The first type of relationship that’s really important, I’ll start with that, is resourcing. And that’s where we can get a lot of good information around the causes of things like bottlenecks. So resourcing can come in a couple of different fashions. The first is obviously human resourcing so there’s a lot of steps and processes that require a person in order to execute and that’s where you can detect a lot of bottlenecks where you have a certain amount of time that’s required for a step to complete and that is consuming a human resource for that time and you simply have not enough of them. The other kind of resource you might have is you could have other sorts of general or operational resources that could have things like quantity. So physical resources, for example, that is like a manufacturing context, you have a hopper with a certain number of widgets in that hopper, and you need to pull them into your line in order to manufacture them into the next thing. Or you could have other consumed resources, perhaps even budgeted resources like a number of API calls at a certain cost, and then above that number, that cost goes up. And so there’s interesting human and non-human resources you would attribute and relate.
Roland: And that’s also some additional things that you might want to think about when you think about simulation as a forward-looking exercise. These are things like schedules. When you think about a retail scenario where you have Black Friday and the holiday season where you need more people because people buy gifts, you know, so you need more people in your store so that you can serve your customers versus other times in the year where you have fewer and you might have people just part time instead of full time. And all those things. And these are things that you can put in a simulation engine and don’t be afraid, it’s not hard. You know, it’s like literally filling out fields; you don’t have to develop the algorithm. That’s what the simulation engine does for you. But those are things to a degree of granularity that you can put in those so that you get a good estimate.
J-M: Absolutely, and then the last thing for understanding whether or not something is costing a lot of money is going to talk about the costs of individual steps and resources. And potentially, if you’d like, to extend the idea of a simulation even to risk and risk cost risk probabilities so you can understand the total cost of a process and get a much clearer sense of where risks are occurring and where costs are occurring. And so particularly, costs can be applied to single steps, so you can have an activity that has a known cost to it. A perfect example is using external resources. I worked with an innovation company that was using an external legal service for patent filing. Every time they hit that step there is a certain number of dollars that gets withdrawn from their account for providing that service. Conversely, you could have costs allocated to your own human resources and so every minute you’re expending the time of a customer service representative. You’re paying their salary and so you can now start to do things like activity-based costing. Or you can do process costing and you can see where costing is coming from? Where are things being charged to you? Where could you shuffle resources to better optimize for this scenario you’re looking to fill without breaking the bank? And so there’s really an important piece of that puzzle from a simulation perspective, to have all these both attributes and relationships to make those assessments come to life.
Roland: Yeah, I agree. So again, just to repeat it, I think there’s a difference between the reengineering of the process flow and the optimization of resources, and depending on who you ask, they might have different priorities on this.
J-M: Yeah. And there are some vendors who believe very strongly that resource optimization is the be all and end all, and I think that the biggest thing you can do for an organization, the real transformation happens in reengineering, not just moving around the numbers of people you have in each role or the number of minutes you’re willing to spend on each task.
Roland: But J-M, talk to me a little bit about what the outcomes of a typical simulation are.
J-M: Yeah, that’s a great question. There’s a few different things you can get out of simulation, which I really, really believe in. Number one is that simulation, when you calculate it, can show you where your process bottlenecks likely are or will be if you choose to implement the process as designed. And that’s by the allocation of resources. Remember, we talked about that before. So when you’re saying I have a certain number of people available to do this process, I have a certain demand curve on my process. Is this going to work? And of course you can see where those bottlenecks will happen and you can see the causes of them by looking at things like utilization in your resources. So that’s really cool. Second thing is you can also optimize that resource model so you can filter in roles based off the resource utilization and say: hey, I’d like to have more people in this role than that role because I have an imbalance and I want to move tasks to the lowest cost resource possible that can still accommodate the task. And that’s going to allow us to have a much better financial model for the execution of this process. So when we’re redesigning it, we’re using resources appropriate to the tasks assigned. The third thing is we want to look at optimizing our actual flow. And that flow is going to come with a couple of different things. The first is understanding variant paths, and so how many of these are actually necessary versus where people are just doing their own thing because they think that their particular “process baby” is special. And also the decisions associated with variation. So what are the decision trees that are causing you to go down these variant paths? Should we be using these same rules, or should we be changing them because we can’t, for instance, accommodate this much variation, or we can’t accommodate this many processes heading down a more costly and effort-filled path? And that’s the fourth thing that I love (and I quite love this) is future proofing processes. It’s a really great outcome of simulation. What you can do is you can say, well, I’ve got a demand on my flow, so a certain number of process executions per week, month, year. What happens if this increases? What happens if this is done 5X 10X? What if this becomes a really important process for the organization? What would happen? Where would it break first? And how can I prepare today to scale up resources to ensure that it’s never seen by our customers? The process continues to work and function as our demand spikes because we have a resource planning model in place. And lastly, and I think this is perhaps one of the most useful things for everyone listening in here, is you can use simulation as a driver for business case development. When you’re doing activity or process-based costing, what you can say is: “hey listen today based on the numbers we see, it’s costing us X dollars”. Tomorrow, should we implement one of these bunch of what-if scenarios, this is how much the process would cost. This is how much we would save by running this implementation.” So when we can do that, we have a much stronger number around the business case for transformation, and so when we’re looking at putting things into our high level program and road map (this is part of the discovery side of things) we can say this is our goal based off the simulation we’ve done and based off the anticipated business benefits. Let’s enshrine that in our mandate.
Roland: That is true, and I think the biggest winner from my side for simulation is actually that you can get all that information before you even start wrenching. Before you even buy a future state system, before you even set up servers or buy cloud space and whatnot, which obviously will be part of your business plan. You could see the effects and then you can make a conscious decision based on your schedule, based on your resources – human, non-human, all that stuff that J-M just spoke about, to make up the idea of “what’s the benefit”? What do I get out of it? And it’s quick, right? And that’s obviously very helpful. But let’s get to the second example. J-M: process mining. You know what is the difference between process mining and simulation now?
J-M: Yeah, that’s a great question and we talked a lot about process mining on this podcast, but just to be clear where things are, process mining often feeds into simulation, but it’s a very separate process. Mining is something you’ll do usually ‘before’, and hopefully often ‘after’ the whole puzzle, because to get the data for simulation you need to have data. And that data often comes from those transactional systems that we’re measuring. So process mining is going to provide an understanding of what’s running today, how it’s working, and what are some numbers around times and resource allocation and things like that that we can use to feed into simulation. The other half of process mining is we can use that as a check for actual goal achievement. Remember, we talked about future proofing and business case development. Well, how do we best prove that we’ve met our business case? Use process mining to check back to say: did we achieve those goals? Did we meet our simulation’s expectations and if so, wonderful, we can continue on. If not, we have to maybe adjust course and that’s where we stay agile. That’s where we use that. The ability to change our solution as we go with one transition state at a time to be able to adapt to what we discover from process mining and that check back.
Roland: I agree it’s not an “either or” it’s a “AND” that we have here. But to come back to process mining. When you look at when I look at process mining, I see basically 3 phases in a process mining project. The first one is getting the data, getting the systems connected to your process mining tool. Get the reference process which might be the one that you simulated and determined to be the best one. Get them into your process mining tool to be able to check compliance as we’ve discussed before. That can be a project in itself because most clients that I’ve seen don’t have a properly documented application landscape, or they’re asking questions like what shall I measure and which KPI? And when you’ve answered that question, they say: “where do I get this from in my highly customized Oracle ERP system that I don’t have the slightest idea in which table information is in?” You see these types of head scratcher situations there. The second phase is then doing the actual analysis. And that basically builds on your hypothesis. What do you want to know? Which is another big hurdle for clients that I’ve seen because they don’t know what they want to know. So you can obviously run base characteristics and base analysis like frequencies and throughput times, and you might find bottlenecks and whatnot. But it’s obviously even more valuable if you have some idea what the thing is that you’re looking for in your analysis .Because that allows you then to build up custom dashboards.
J-M: We talked about this in our previous season, but we talked about the idea of suspicious areas. What are you seeing that looks like it could use a little bit of love, and I think that’s a really important sort of direction rather than sort of running in a bunch of different directions and trying to figure out where to go next. That’s going to give you a good point. Or a north star.
Roland: Which is a very good point. So your analysis is not a one-and-done exercise. It’s literally the iterations that you run. So I typically like to do this as OK, bring in the data, run ”initial, standard process mining.” You build up the explorer, and you build up whatever dashboards you typically use, which is actually meant for data validation, right? Because you want to have the client buying into this and trusting the tool even though they might not like the outcome that they see. “Oh no, we don’t do these so and so many variants of this.” Yes, you do, you know, and then they might argue, no, your tool just stinks.” And that’s the first thing. So do a base process mining analysis and have the client validate the data and then based on that you might have 1/2/3 more iterations because you might see some spikes in there. You might see some things that don’t smell right and you might have the interest to say: “hey, why does this take so long?” Or why do we have so much rework in our process? So the message is it’s not a one and done it’s multiple iterations. Also, when you think about a process mining project where clients will have to pay for things, you want to set some limits. You want to go and you want to say: OK, we’re going to do two or three iterations, because otherwise it could be an endless loop where the client demands more and more and more, and your statement of work is poorly written, and then you’re on the hook for this. The main idea of this is obviously to get new ideas for improvement. It’s getting new “requirements” for the next iteration of our solution lifecycle.
J-M: Yeah, and the last piece of the puzzle I wanted to talk about is what you do with the technical outcomes of this kind of exercise in process mining, where you pull information back into the execution layer. Remember, we talked about these five steps of the solution lifecycle? Well, from Measure and Analysis there’s some good connections. One is back into process execution, and you can use this kind of monitoring system as a ‘next best action’ system for process executions. Let’s course correct along the way – we’re seeing areas of a process struggle in ways that don’t necessarily require reengineering. They simply require simple practice changes or slight rules changes. Things like that, things that we can do without having to do a huge amount of work, make a big difference to how our processes run. And so actions and notifications can go to users, and those users can change their behavior, or small changes to things like decision tables can make a big difference right away. And then, taking forward information that you can take from that process mining exercise. Real business models that you can use in the next iteration of that design and program road map. And so let’s take back the model, not the one we thought we had, but the one we actually do. What our as-executed is from our first iteration of change, or our Nth iteration of change, and we can say, here’s what we’re doing today. Here’s our new baseline. And so each time we iterate, we establish this new baseline. This new baseline becomes the new analysis model. The new proposal for improvement, and we can dynamically adjust and course correct it to make it more relevant to what’s actually happening today. That’s really important, and those are both technical solutions, but they feed into the people and the process by which we are trying to improve.
Roland: So, dear listeners, this brings us to the end of our second segment, but this time I’m going to send you in our little break with another couple of questions. So, for example, have you thought of what information you have about your process? Being it forward-looking or in hindsight, with the two examples that we just gave, where does that information come from? How does that information connect with your desired outcomes? So, for the little break that we have now, think about how you currently handle those practices and think about if the solution lifecycle will help you in articulating and finding the right information going forward.
Musical Interlude: “Lofi Lobby Loop”, Jeremy Voltz
J-M: And we’re back. Hey folks, thank you so much for taking a couple of seconds to think about the information you have about processes and what you’re going to do with it. Well, let’s talk about ‘why’ and the meaning / the value of all this solution lifecycle discussion. And Roland, first and foremost, tell me where I can extract value from using this solution lifecycle as a guide for how to make things better.
Roland: So the first thing is: it’s the life cycle is, as I said before, it’s the mantra of “you build it. you own it.” So it’s an iterative circle. It’s not a one and done. But while you’re doing that, obviously, the big value is that you use data-based decision making. Or when J-M spoke about simulation and how to build your business case, that’s obviously not built out of thin air or weird assumptions. It’s based on what you discovered in your as-is right, and then you apply human logic to it and change your process or your simulation accordingly.
J-M: Yeah, I’ve been using the phrase “evidence-based decision making” with a lot of my clients and it’s really resonating because people don’t want to think of themselves as making decisions without the evidence to make them. But the truth is, well, they often are. And so when you have the solution lifecycle that you’re beholden to, you’re trying to make sure that you cover off all these steps. One of them is going to involve getting information, real data, and using it effectively. The second piece of the puzzle in getting value is something that somebody I respect quite a lot said: if you have a system that’s going to require that you work really hard to create every business scenario essentially from scratch, when you present these business scenarios to your senior leadership, you’re going to present one or two. But when you have a system and a practice that allows you to consider a bunch of ‘what-if’ scenarios and bring a few different options to the table without a huge amount of effort, you’re going to have a lot more choice and you’re going to be able to more finely hone the decision into what your company actually needs. So ‘what if’ scenario creation is a lot easier when you have this information in place? When you’ve got that solution lifecycle driving the development of business cases, the driving the development of developments, that’s going to give you a lot more value, and it’s going to help you make better decisions for the organization.
Roland: Yeah, and then lastly, the third point is: it’s like driving a car. You don’t drive your car by looking in your rear view mirror. Don’t fall victim to the claims of some process mining vendors when they say: “you don’t need a future state, you just need the as is. You know what we find here and then you can adjust in an agile way”. I think all those traditional techniques, traditional analysis that you do, simulation that we spoke about, still has a place in the toolkit of modern architects. So J-M, we spoke about the values, but as always in life, there’s obviously some points of concern. Some cautions that you might want to tell our listeners.
J-M: Yeah, I, I think that there’s a couple things I wanted to just warn everyone around. First and foremost is that as you’re going through the solution lifecycle and you’re using data as a driver, notice that you might have holes in your information. There’s oftentimes systems that won’t be built to capture data from, or manual processes that you haven’t got information in, so you’re going to have holes in this data. Now there are a couple of ways to approach holes in your information. The first is, of course, to fill the hole. There’s a lot of real temptation to put black boxes in where you don’t know information and just leave it for later. And in some cases, that can be good when you have a process where you know the start time and end time, for instance, of two steps and you know there’s a step in between, you can do this intermediate analysis where you say, OK, well, we guess there’s a step in here and here or some number of steps, and this is how long it takes. But when you’re black boxing information, there’s a real temptation to just ignore it. Particularly when that black box comes from a different department. Where you’re crossing an organizational boundary, and it seems like more hassle to find that information than it is worth to pull it together. I have to caution you: data holes create more holes and you can have compounding errors in your analysis based on a lack of information gathering. So, bring people to the table, bring other groups to the table, get their input even if that input is in a different format, translate it and incorporate it into your analysis as much as possible. That’s really important. The other piece of the puzzle about data is about coarse data versus fine data. People can get sucked into the very very weeds of individual user actions with task mining, and that’s a lot of detail. Or they can get stuck in the clouds with process mining or business analysis. To say, look, generally these sorts of things happen and we sort of see the rough recourse transactions happening here and there. We don’t necessarily know what’s happening. You want to get down to the logical process level. And that might mean rolling up the insights you received at a task mining level to the higher level. And so you have to give away some of that fine granularity you’ve paid for in order to be able to properly contextualize it at the level you can use it at. Conversely, you might have to pay more in terms of human resource time in terms of technology to get deeper than your high level steps. If you have a process (and I’ve seen a bunch of clients you send this to me) for example, for materials and service ordering, and you say it’s four steps. No, it’s not. It’s probably more like 30 or 40, but it’s not 700 for sure. There might be 700 user actions, but you want to get to that middle layer. So beware of coarse data and be aware of fine data one is going to confuse you and the other is going to infuriate you. Keep them at the level that you can affect – this process level, when you’re looking at data. Those are some cautions along the way as you’re incorporating data into your solution lifecycle. And the last caution, I would say, is something that I say essentially every episode: remember that your business is composed of people. You have systems, sure. You have processes, yes, but the people are the ones doing the work. And so never forget to involve them throughout this process. Involve your stakeholders. Make sure that they’re brought into the place that they need to be to contribute their ideas, their expertise, their context into everything from your roadmapping and planning to your solution designs, from your actual implementations to your executions to what you’re measuring. The people are going to be an excellent source of information, and most importantly, you’re going to earn their trust and buy in when you bring those stakeholders into place. What do you think, Roland?
Roland: Agreed, maybe that Third Point as a takeaway that we have is that the full lifecycle that we spoke about is iterative, right? It’s not mentioned that a couple of times by now it’s not ‘one and done’, right, and the idea is more from a philosophical perspective is to put in that concept of improving what you have over and over continuously. This also fits well and I mentioned that before as well, with the idea of ‘you build it, you own it’ that we see in DevOps, but it also fits nicely into concepts that you see, for example in Scaled Agile when you need to build a runway before you actually develop the solution on top of it, before you use the runway. And I don’t know if he will have it done by time, but I’ve reviewed a first draft of a little doodle video that Mike Idengren, who was guest in our episode 6 and spoke about Agile and Architecture, is currently creating which I really like because it’s about the connection between the landing of a space shuttle and the implementation of solutions in a Scaled Agile way.
J-M: But no matter what, keep your eyes peeled onto whatsyourbaseline.com as we link in some of our favorite articles and doodle videos from thought leaders we love.
Roland: Definitely, oh yeah. Even if we can’t get it done within the next couple of days, I will follow up with him. We will post it as a blog post. And then the last takeaway I think is that this approach will build up your enterprise baseline. Your first phase of the lifecycle over time. Which means you don’t have to have that big effort upfront needed. And we’ve discussed that in previous episodes, especially the “10 Things I’ve Learned” when you think about, how do I build all that stuff? My organization is so huge, you know, think about a national bank or even an international bank. There’s so many thousands of people there. So how many processes do you have? Don’t get stopped in doing this type of analysis just because you are a huge organization. Take it one bite at a time.
J-M: That’s a great lesson. Take it one bite at a time and that makes it a lot easier to consume. But most importantly, that lets people build together rather than having a giant mandate from the top that requires everybody do one thing at one time and that’s the kind of thing that fails because there’s pushback. But over time you can build up something beautiful together. I wanted to turn this into a call to action to everyone here. All of our dear listeners. Our last call to action for today. Tell us about your experience or think about your experience. By the way, you can provide feedback. We’ll talk about that in a second. But think about your own experience. Where does our model and our experience differ from yours? What are you doing today around that solution lifecycle and does it work better than what you were hearing here? And how can you synthesize a path forward based on the solution lifecycle we’ve presented today and the realities of your own business scenario? We’ll come back in a moment for our last thoughts and conclusion to today’s episode.
Roland: Welcome back to the last segment of today’s show. In this show, we spoke about these solution lifecycle. We discussed what a solution actually is, which is more than software, if you might remember. We spoke about the different layers in the life cycle which are Design and Execution and the five phases of the life cycle in our first segment. And then in the second segment of the show we spoke about the application. We looked at simulation, which is forward looking / future state and we spoke about process mining which is a more as-is analysis and backwards looking exercise. And in both cases, both are needed in a proper system. And then in the last segment we spoke about the value, the cautions that we have the iterative characteristics of the lifecycle, and obviously the effort that is needed to build up all that stuff, and where we said you don’t need to have that big effort upfront, build it as you go. You build it, you own it.
J-M: Absolutely! Well, that was a wonderful episode and a great kickoff to our second season. And thank you so much for all of you helping to make this happen. It’s the listeners like you that make it really great for us to do what we do. And in consuming / giving us feedback? Well that’s just wonderful for everyone. So, that’s a reminder to everyone – please do give us lots of feedback. Thank you for listening, but if you’d like to reach out by email, please do so at hello@whatsyourbaseline.com? Or you can even leave us a voice message on Anchor. And please leave us a rating and review in your pod catcher of choice. Those help us to defeat the algorithm, but also give us a good sense of what we can keep improving on as we go through our own iterative design process for the What’s Your Baseline podcast? And as I’ve mentioned before, and as we mentioned every episode, please feel free to visit our website at whatsyourbaseline.com where you can find the show notes and the graphics for this episode at whatsyourbaseline.com/episode13 . Well, as always. I’ve been J-M Erlendson.
Roland: And I’m Roland Woldt
J-M: And we’ll see you in the next one.
Roland Woldt is a well-rounded executive with 25+ years of Business Transformation consulting and software development/system implementation experience, in addition to leadership positions within the German Armed Forces (11 years).
He has worked as Team Lead, Engagement/Program Manager, and Enterprise/Solution Architect for many projects. Within these projects, he was responsible for the full project life cycle, from shaping a solution and selling it, to setting up a methodological approach through design, implementation, and testing, up to the rollout of solutions.
In addition to this, Roland has managed consulting offerings during their lifecycle from the definition, delivery to update, and had revenue responsibility for them.
Roland has had many roles: VP of Global Consulting at iGrafx, Head of Software AG’s Global Process Mining CoE, Director in KPMG’s Advisory (running the EA offering for the US firm), and other leadership positions at Software AG/IDS Scheer and Accenture. Before that, he served as an active-duty and reserve officer in the German Armed Forces.